Dema’s profit-based lifetime value (LTV) forecasting engine transforms your
historical customer behavior and transaction data into precise,
forward-looking customer lifetime value predictions. These intelligent
insights empower you to optimize customer acquisition costs, implement
strategic retention campaigns, and allocate marketing resources with
confidence—identifying high-value customers and preventing churn before they
impact your bottom line.
How to access
You can access the LTV forecast directly from the platform’s Reports section. It is available as a selectable metric and can be explored at multiple levels of granularity—including down to the individual customer level. When applying the LTV metric to broader dimensions such as Country or Store, the platform displays the average forecasted LTV of customers who made a purchase within the selected time period. This allows you to assess expected profitability across different regions or store locations. Because LTV forecasts are updated daily, the values shown are always the most recent predictions available, even when viewing historical timeframes. Consequently, past dates reflect the latest forecasted LTVs rather than the original values calculated at that time. This forward-looking approach ensures the data reflects your customers’ most current expected behavior.How our forecasting engine works
Core algorithm
The system is built on gradient boosted decision trees, an advanced
algorithm architected for large-scale customer datasets, delivering speed
and accuracy for lifetime value forecasts.
Continuous model learning
The system incorporates new customer patterns, seasonal behaviors, and
market changes to maintain forecasting precision throughout your business
cycle with monthly training and daily prediction updates.
Core algorithm
The engine employs an ensemble of gradient boosted decision trees that systematically analyze your customer data through intelligent questioning patterns. For example: “Did this customer demonstrate strong engagement during recent periods?” or “How did similar customers in this demographic perform during comparable periods?” By aggregating insights from thousands of these decision trees, the model generates comprehensive customer lifetime value forecasts. This approach provides more stable and actionable forecasts for strategic customer relationship planning.Features
The system uses a combination of historical customer behavior indicators, transaction analysis, and temporal context variables to create a comprehensive feature set to forecast future profit-based LTV. The target variable employed is the Gross Profit 2 metric.- Customer engagement velocity and seasonal patterns
- Geographic and demographic variations
- Purchase frequency and monetary metrics
- Product category preferences across customer segments
- Channel performance and acquisition source history
- Marketing response activity across available customer hierarchies
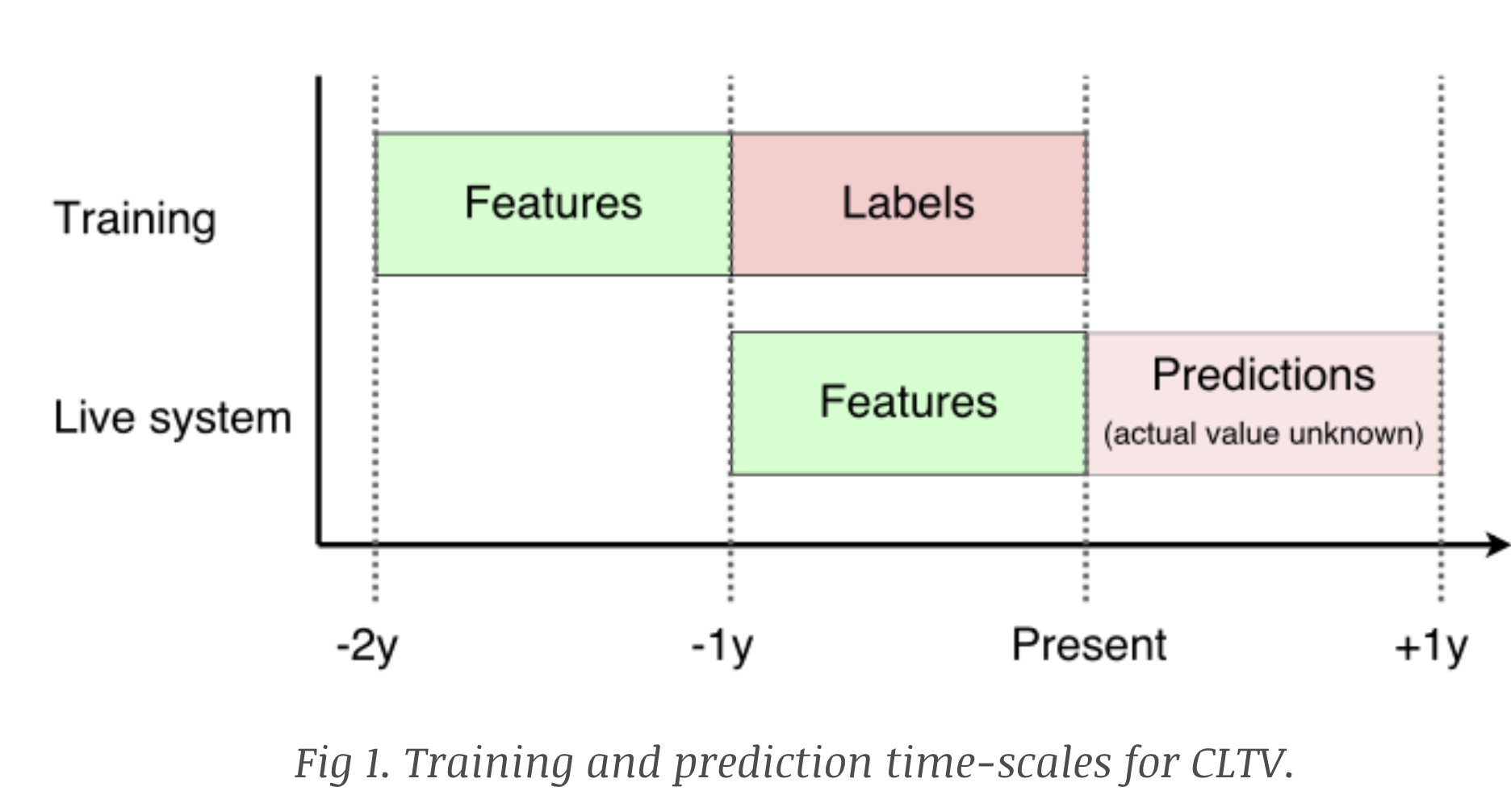
Training time scales
The temporal relationship between features, labels, and forecasts is essential for constructing a robust model. The diagram below illustrates the time-based strategy used to define training and forecasting windows.